先日、会社の朝会スピーチの当番が回ってきたので、「食生活を改善しようとしています、ぜひアドバイスください」という旨の話をした。すると、![]() id:Windymelt さんが生活術紹介記事を書いてくれたり、
id:Windymelt さんが生活術紹介記事を書いてくれたり、
他にも会社の人がいろいろアドバイスをくれた。せっかくなので、教えてもらったことを記事にして公開しておく。
まず、スピーチのプレゼン資料がこれ。
朝会スピーチ2021/09/21
前回朝会スピーチに当たったとき、おすすめの食品について紹介しました。しかし、そればかり食べる生活を続けていたところ、健康に悪影響が出たので、そのことについて話します。
今までの食生活
- ご飯パック
- レトルトハヤシライス or ふりかけ
- 堅あげポテト or じゃがりこ
健康への悪影響
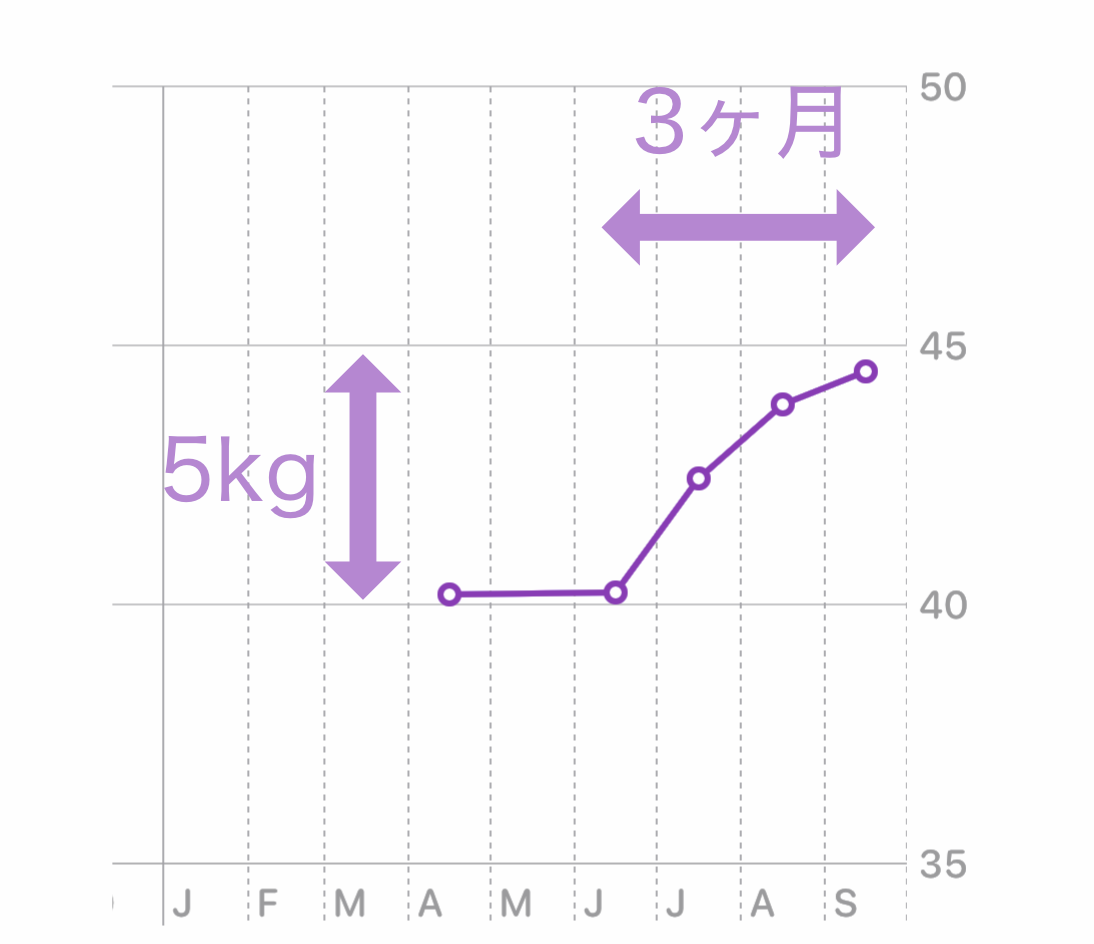
1. 太った
3ヶ月で 5kg 増えた 2. 食後の異常な眠気
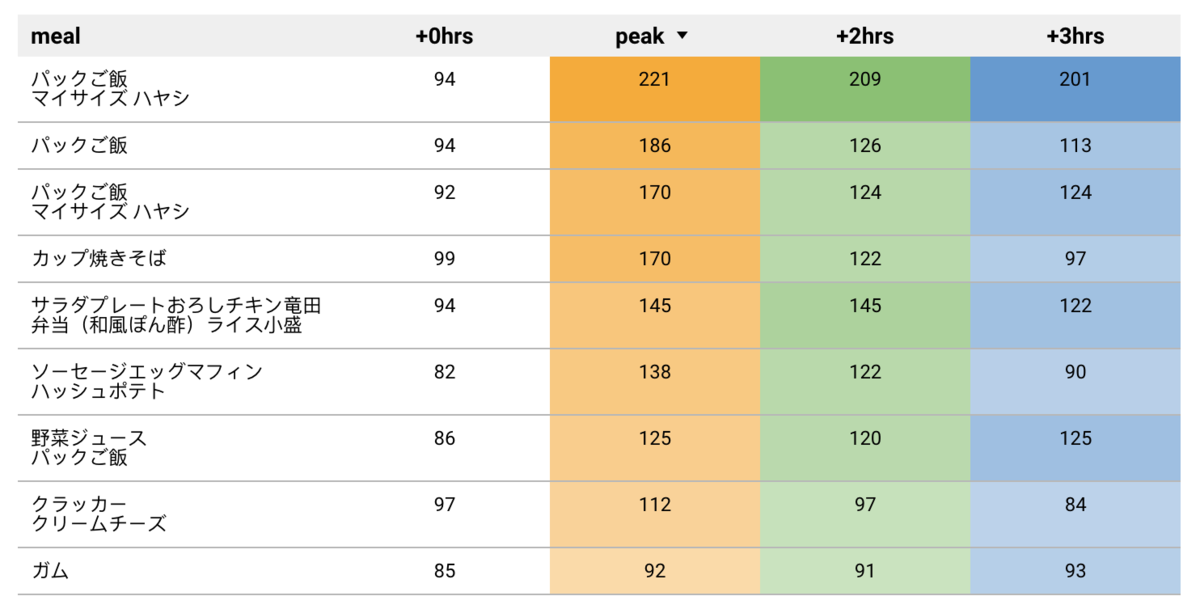
「血糖値スパイク」といって、食後に血糖値が急上昇→急降下する現象が原因。 眠気を引き起こすだけでなく、血管にダメージを与えるなどいろいろ体に悪い。
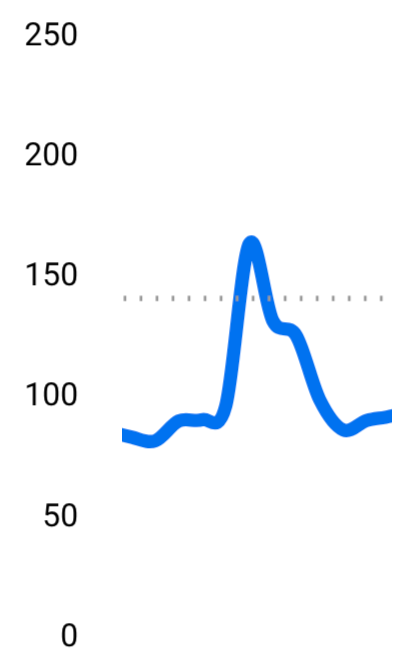
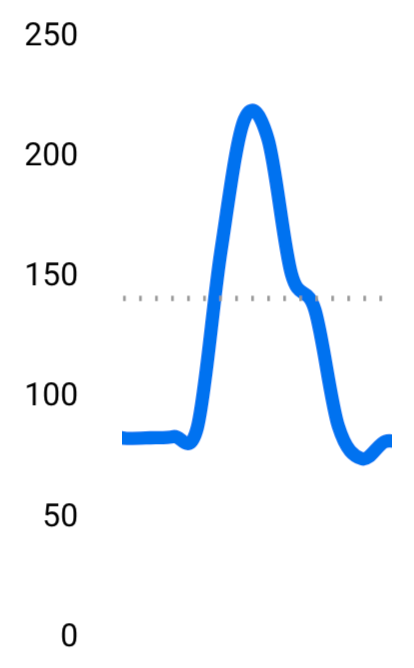
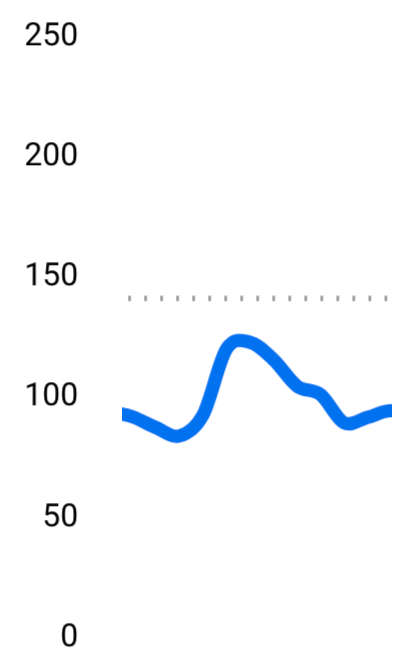
おおよその血糖値グラフ 食後に血糖値が激しく上下している。一応緑のエリアが正常な範囲ということになっているので、だいぶ逸脱している。
3. 歯が欠けた
食事が原因かはわからないけれど、カルシウム不足の可能性もある?
改善した食生活
(本腰を入れ始めたのは10日前くらいから)
- 野菜ジュース
- 炭水化物の前に摂ることで、血糖値の急激な上昇を抑える
- オートミール + 牛乳
- ご飯よりカロリーも糖質も控えめ
- カルシウムを取れる
- サラダチキン
- 肉要素
完成図 食事改善の効果
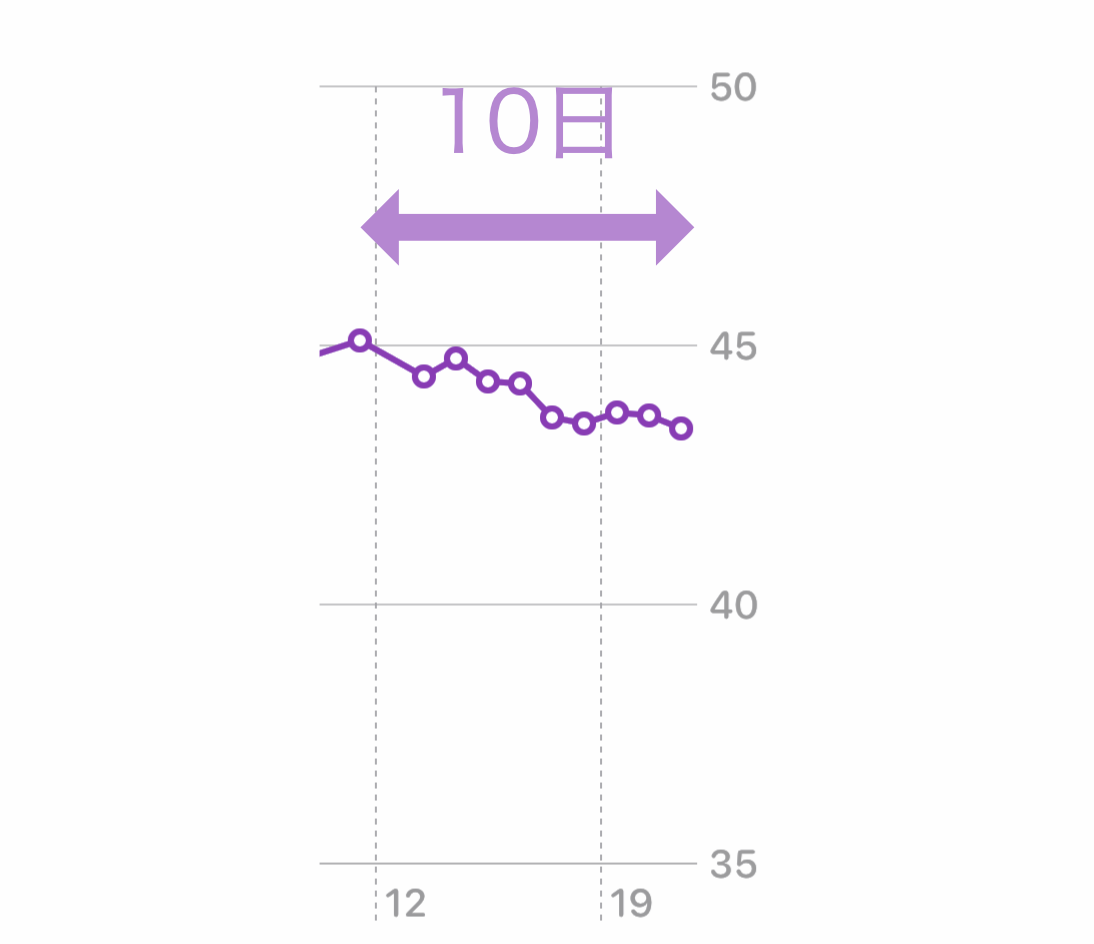
1. ちょっと痩せてきた
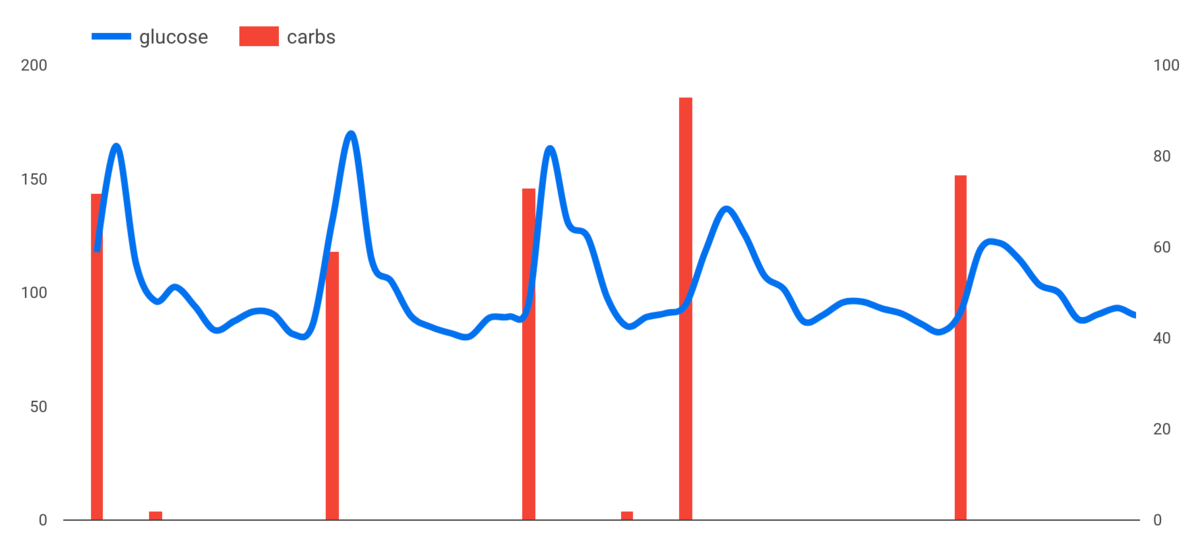
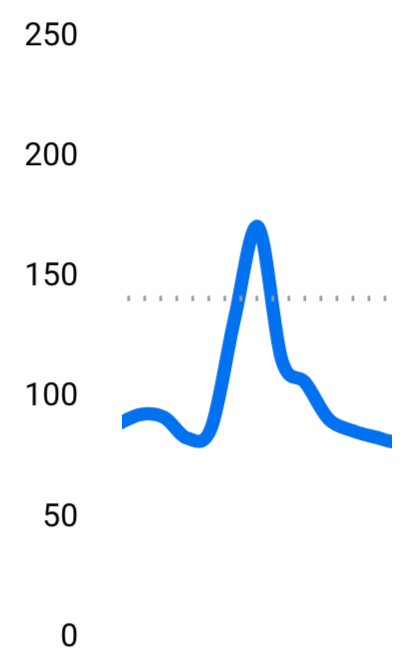
減少傾向 2. 血糖値
Before After かなり穏やかになったし、正常な範囲(緑のエリア)に収まるようになってきた。
3. 歯
まだ効果はわかりません。欠けないように頑張ります。
食事改善初心者なので、もし他にもやったことが良いことがあればぜひ教えてください。




こういうスピーチだった。
以下では、会社の人たちからおすすめしてもらったものを、私が試してみたものとまだ試せていないものに分けて紹介する。
もう試してみたもの
BASE BREAD(完全栄養食)
いろんな栄養が含まれている上に日持ちするパン。
教えてもらった後早速注文して食べた。ほかほかもちもちしていて良い。独特な味はするけど、牛乳に浸して食べたら気にならなくなった。これからも続けたい。
nosh(宅配冷凍食品)
数日分の料理を選ぶと、冷凍で送ってくれるサービス。
私は以前使っていて、主菜は美味しかったけど、副菜の味が濃すぎて大量の米と共に食べる羽目になるので、炭水化物の摂りすぎが気になって中断してしまった。今思うと、米じゃなくて豆腐とかと一緒に食べたらよかった。
小腹が空いたらタコを食べる
ヘルシーな上に歯応えもあるので、間食にはぴったりらしい。仕事中に食べてみたら満足感があった。
あすけん(食事記録アプリ)
食事を記録していくと、摂取栄養素を計算・可視化などしてくれるアプリ。おととい存在を知って使い始めた。
類似アプリである FatSecret を使っていた時期もあったけど、あすけんの方が栄養素グラフが見やすかったり表示される栄養素の種類が多かったりするので、こちらに乗り換えた。
例えば、私の今までの食事と改善後の食事をあすけんでグラフ化するとこうなって、差がわかりやすい。
| Before | After |
|---|---|
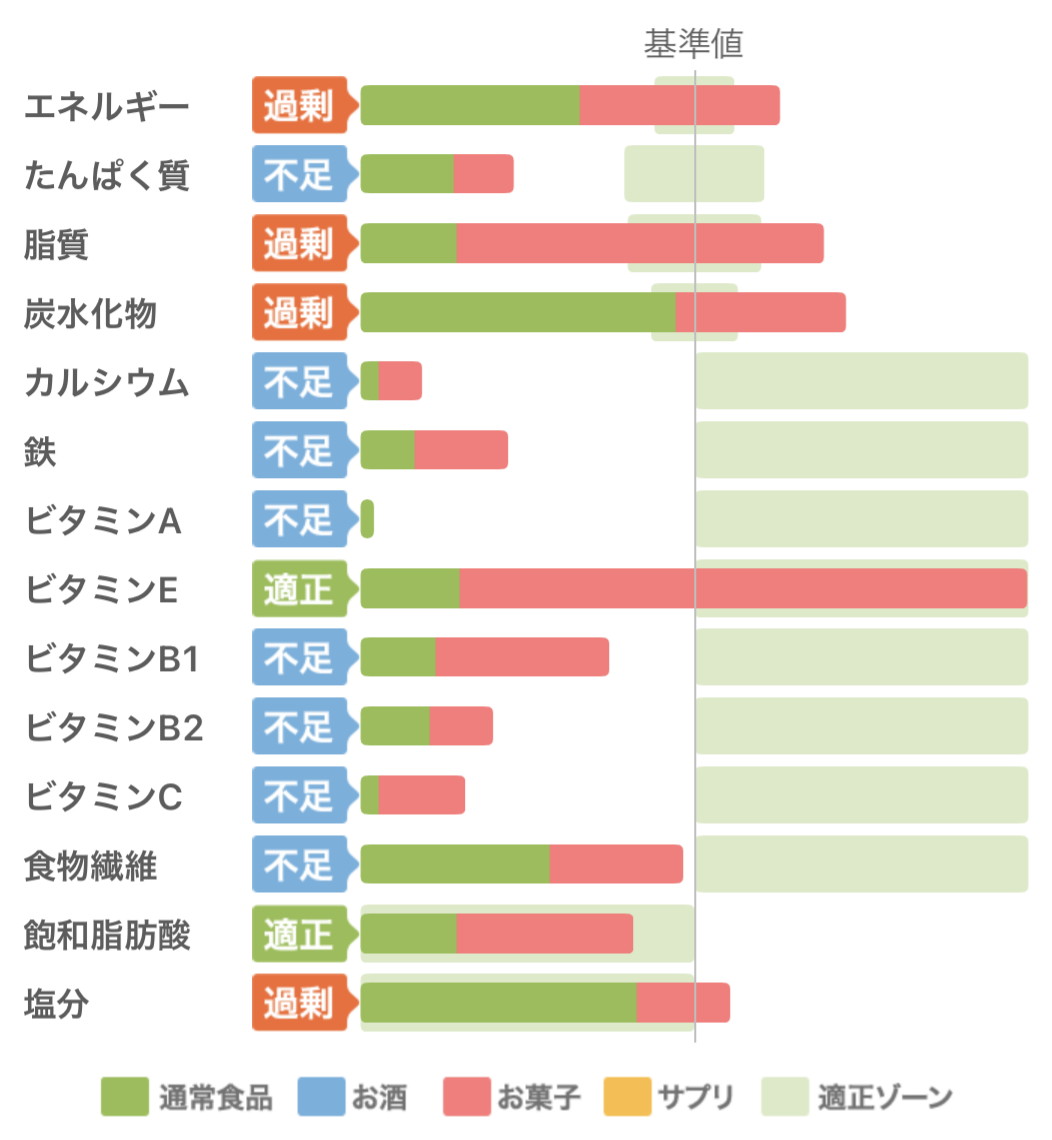 |
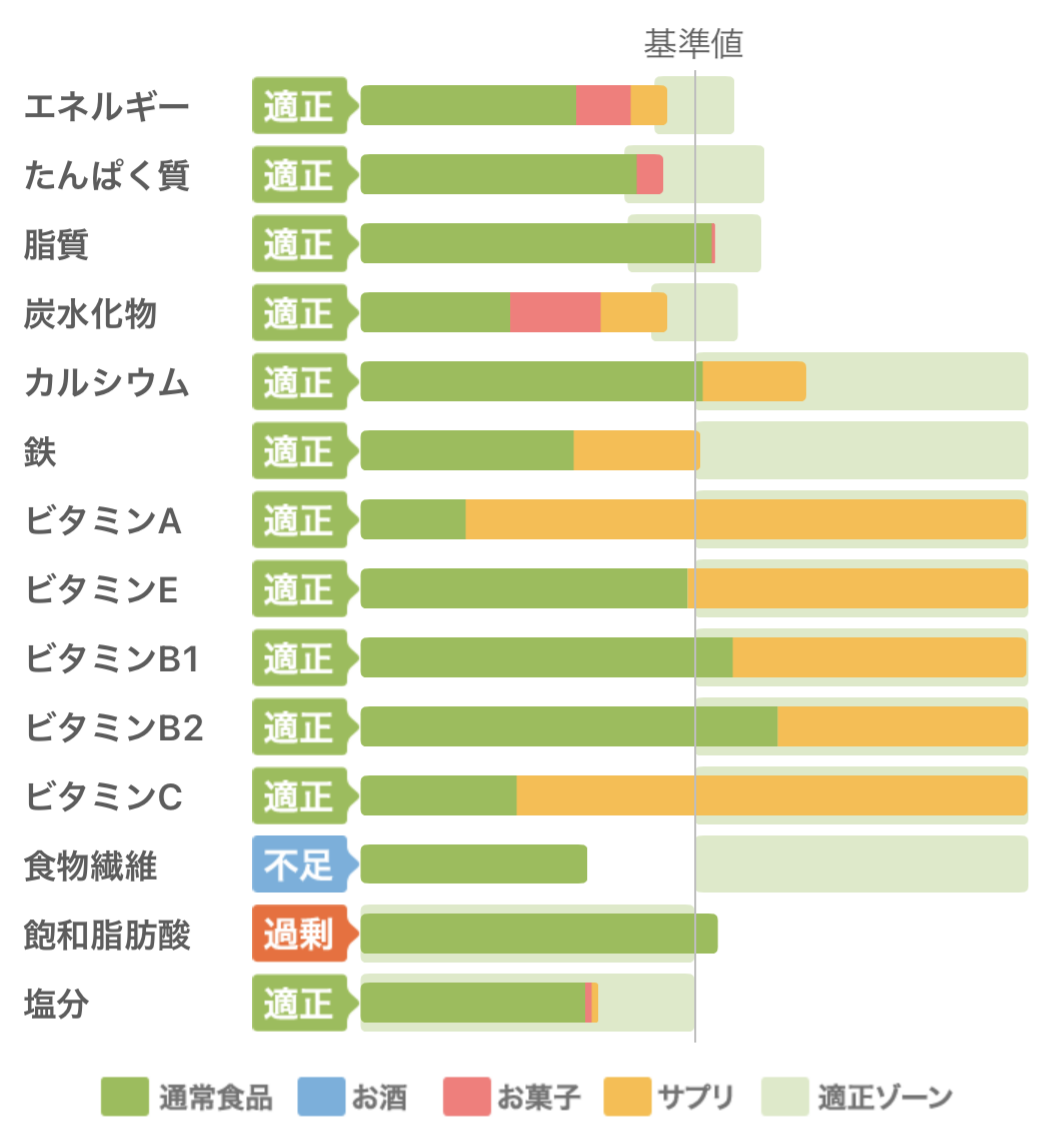 |
ユーザーの公開日記の雰囲気は、FatSecret の方があっさりしていて好き。
まだ試せていないもの
COMP(バランス栄養食)
BASE BREAD が合わなかったら COMP を試す予定だったけど、BASE BREAD で満足してしまった。
黒ごまきな粉アーモンド + ヨーグルト
肌にとっても腸内環境にとっても良い食品らしい。肌または腸の調子が悪いときに試してみたい。
食洗機
生活の効率化に欠かせない便利な機械だと聞く。
今は、皿にラップを敷くことで皿洗い不要の暮らしをしているので、まだ食洗機は必要ないかなと思っている。
鍋
鍋を作ると、野菜とタンパク質をたくさん摂れるので良いらしい。
しかし包丁を使う必要があるので、少し精神的なハードルが高い。包丁とまな板が水切りラックの上で一年半くらい乾かされ続けているので、まずはそれを何とかする必要がある。
そもそもキッチン全体に近寄り難い雰囲気があり、やむを得ず近づくときも無意識に息を止めて目を逸らしてしまうので、なかなか料理に踏み切れない。
その他教えてもらったこと
歯が欠けるのは、カルシウム不足などではなく、歯ぎしりが原因である場合が多い。マウスピースを使うと良い。









{kind=link}